People store large quantities of data in their electronic devices and transfer some of this data to others, whether for professional or personal reasons. Data compression methods are thus of the utmost importance, as they can boost the efficiency of devices and communications, making users less reliant on cloud data services and external storage devices.

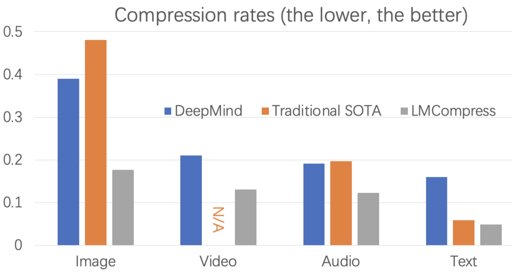
If this really is lossless, it is incredible. I’m skeptical until I see it in action though.
Lossless is the big claim that nobody is fixating on because “AI” discussions only ever run one set of talking points.
I get how semantic understanding would trade performance for file size when doing compression. I don’t get how you can deterministically use it to always get the exact same complete output from a partial input. I’d love to go over the full paper. And even then the maths would probably go way, way over my head.
So… crystal ball, I don’t have access to the paper either. Think arithmetic coders as neural nets are function approximators. You send an initial token and the NN will start to generate deterministically, once you detect a divergence from the lossless ideal you send another token to put it on track again. Make it a sliding window so things don’t become too computationally expensive. You architect the model not to be smart but to need little guidance following “external reasoning” so to speak.
The actual disadvantage of this kind of thing will be the model size, yes you might be able to transmit a book in a kilobyte (100x or more compression) but both encoder and decoder will need access to gigabytes of neural weights, and that’s just for text. It’s also not going to be computationalliy cheap, though probably cheaper than PAQ.
Trading processing power for size is a thing. I guess it depends on application and implementation. Well, and on the actual size of the models required.
It’s one of those things that makes for a good headline, but then for usability it has to be part of a whole conversation about whether you want to spend the bandwidth, the processing power on compression, the processing power on real time upscaling, the processing power on different compression tools, something else or a mix of the above.
I suppose at some point it’s all “benchmarks or it didn’t happen” for these things. And when it comes to ML benchmarks are increasingly iffy anyway.
But spending a lot of processing power to gain smaller sizes matters mostly in cases you want to store things long term. You probably wouldn’t want to keep the exact same LLM with the same weightings and stuff around in that case.
Arithmetic coding is one of my favorite algorithms. Any token predictor can be converted into an entropy encoder!
Extraordinary claims require extraordinary evidence.