People store large quantities of data in their electronic devices and transfer some of this data to others, whether for professional or personal reasons. Data compression methods are thus of the utmost importance, as they can boost the efficiency of devices and communications, making users less reliant on cloud data services and external storage devices.

Ok so the article is very vague about what’s actually done. But as I understand it the “understood content” is transmitted and the original data reconstructed from that.
If that’s the case I’m highly skeptical about the “losslessness” or that the output is exactly the input.
But there are more things to consider like de-/compression speed and compatibility. I would guess it’s pretty hard to reconstruct data with a different LLM or even a newer version of the same one, so you have to make sure you decompress your data some years later with a compatible LLM.
And when it comes to speed I doubt it’s nearly as fast as using zlib (which is neither the fastest nor the best compressing…).
And all that for a high risk of bricked data.
I think the idea is to have compressor and decompressor use the exact same neural network. Looks like arithmetic coding with a learned function.
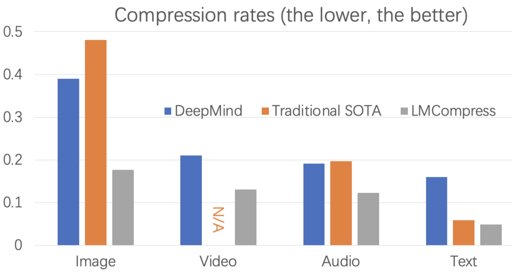
But yes model size is probably going to be an issue.
Ye but that would limit the use cases to very few. Most of the time you compress data to either transfer it to a different system or to store it for some time, in both cases you wouldn’t want to be limited to the exact same LLM. Which leaves us with almost no use case.
I mean… cool research… kinda… but pretty useless.
I’m guessing that exactly the same LLM model is used (somehow) on both sides - using different models or different weights would not work at all.
An LLM is (at core) an algorithm that takes a bunch of text as input and produces an output of a list of word/probabilities such that the sum of all probabilities adds to 1.0. You could place a wrapper on this that creates a list of words by probability. A specific word can be identified by the index in the list, i.e. first word, tenth word etc.
(Technically the system uses ‘tokens’ which represent either whole words or parts of words, but that’s not important here).
A document can be compressed by feeding in each word in turn, creating the list in the LLM, and searching for the new word in the list. If the LLM is good, the output will be a stream of small integers. If the LLM is a perfect predictor, the next word will always be the top of the list, i.e. a 1. A bad prediction will be a relatively large number in the thousands or millions.
Streams of small numbers are very well (even optimally) compressed using extant technology.