People store large quantities of data in their electronic devices and transfer some of this data to others, whether for professional or personal reasons. Data compression methods are thus of the utmost importance, as they can boost the efficiency of devices and communications, making users less reliant on cloud data services and external storage devices.

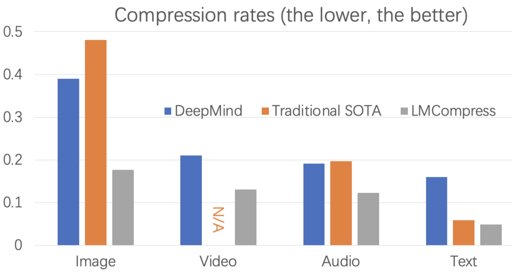
I tried reading the paper. There is a free preprint version on arxiv. This page (from the article linked by OP) also links the code they used and the data they tried compressing, in the end.
While most of the theory is above my head, the basic intuition is that compression improves if you have some level of “understanding” or higher-level context of the data you are compressing. And LLMs are generally better at doing that than numeric algorithms.
As an example if you recognize a sequence of letters as the first chapter of the book Moby-Dick you’ll probably transmit that information more efficiently than a compression algorithm. “The first chapter of Moby-Dick”; there … I just did it.
Very helpful analogy!