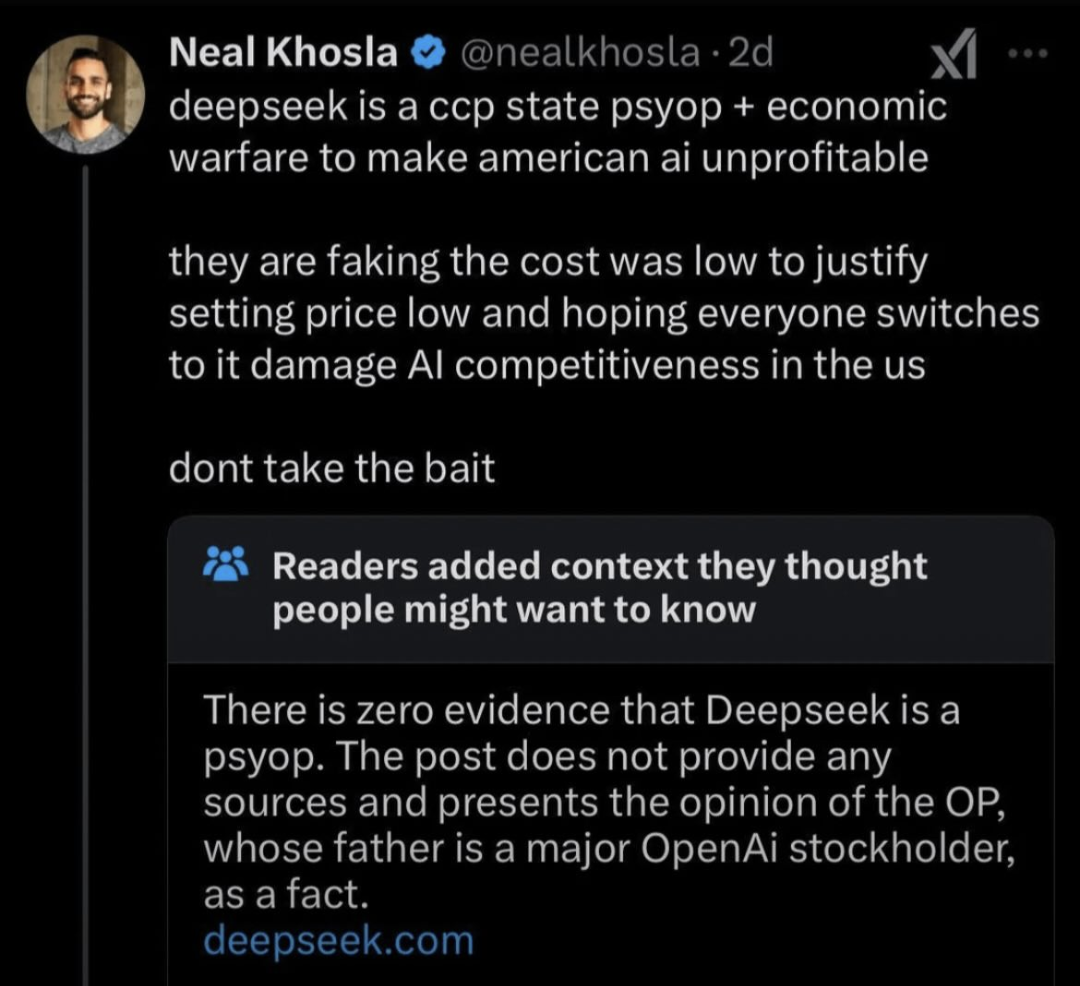
The actual local model for R1 (the 671b one) does give that output because some of the censorship is baked into the training data. You’re probably referring to the smaller parameter models which don’t have that censorship–because those models are distilled versions of R1 based on llama and qwen (the 1.5b, 7b, 8b, 14b, 32b, and 70b versions)
{kind=link}
The actual local model for R1 (the 671b one) does give that output because some of the censorship is baked into the training data. You’re probably referring to the smaller parameter models which don’t have that censorship–because those models are distilled versions of R1 based on llama and qwen (the 1.5b, 7b, 8b, 14b, 32b, and 70b versions)
You can see a more in-depth discussion of that here: trigger warning: neoliberal techbros